Introduction
Analyzing qualitative data is challenging. Such analyses are even more difficult when the topic is controversial and the results will drive important policy decisions. This post explores AI methods for qualitative research, using chatGPT for categorization, embeddings to find hidden topics, and long-context summarization with Claude2 on a case study analyzing free-text public comments to a controversial Environmental Impact decision.
Background
Quite a while ago, I detailed why replacing wolves on Isle Royale National Park was a bad policy decision back by even worse science. Since then, the National Park Service (NPS) decided to commit to wolf replacement anyway, dropping 19 new wolves on the island in 2018 and 2019. The results were expected. The new wolves killed the last original male wolf in 2019, almost certainly ensuring that the new wolf population will be genetically disconnected from the prior population. Of the 20 wolves that NPS attempted to relocate, one died before making it to the island, one voluntarily crossed the ice back to the mainland*, and four others died by the end of 2019. The surviving 14 wolves successfully bred and the population now stands at 31. So, in the end, we have a new, synthetic wolf population that is entirely disjunct from a genetic and ecological perspective. As I predicted in my original post: “in reality, this is not a genetic rescue project, it is a genetic replacement project,” which violates both the scientific and management purpose of the Park.
* This contradicts one of the primary justifications for replacing the wolves. Proponents argued that the lack of ice due to climate change would make natural repopulation impossible.
But neither science nor policy drove NPS’s decision. Management of charismatic mammals, especially in a well-known National Park, is largely a matter of public sentiment. In fact, it is a codified part of the decision process. Federal managers are required to seek public comments as part of the NEPA process.
In general, I am a huge supporter of public voices in important conservation decisions (I’ve even written papers advocating for it). But, sometimes I worry about how advocacy groups can skew the perception of organic public sentiment. That’s what I’d like to analyze in this post.
All of the public comments submitted to NPS on the Isle Royale wolf-moose management plan are public record. You can download and read all 1117 pages of comments.
But 1117 pages is a lot of text to read and digest. In this post, I want to show how you can easily process lots of text using AI (both generative large-language models (LLM), like chatGPT, and LLM embeddings) to make quantitative (or semi-quantitative) analyses.
Basic analyses
Visit my GitHub repo for this project for a fully reproducible analysis.
First, we’ll set up the environment and load in necessary packages.
# Load libraries
library(pdftools) # We will use 'pdftools' to convert the pdf to plain text
library(tidyverse)
library(stringr)
library(RColorBrewer)
# Set up the directory structure:
make_new_dir <-
function(DIR_TO_MAKE){
if(dir.exists(DIR_TO_MAKE) == FALSE){
dir.create(DIR_TO_MAKE)
}else{
print("Directory exists")
}
}
make_new_dir("./data/")
make_new_dir("./figs/")
We can download the comments from the NPW website.
download.file(
url = "https://parkplanning.nps.gov/showFile.cfm?projectID=59316&MIMEType=application%252Fpdf&filename=ISRO%5FMWVPlan%5FAllCorrespondence%5FPEPC%2Epdf&sfid=232552",
destfile = "./data/ISRO_MWVPlan_AllCorrespondence_PEPC.pdf",
mode = "wb"
)
The first step to analyze the public comments is to parse the pdf into text. This is a tedious process. I won’t show it here, but you can follow all of the steps on my GitHub repo for this project.

You can download my pre-processed dataset to short-cut the the PDF parsing steps.
download.file(
url = "https://www.azandisresearch.com/wp-content/uploads/2023/09/EIS_comments.csv",
destfile = "./data/EIS_comments2.csv"
)
EIS_comments <- read.csv("./data/EIS_comments.csv")
The formatting follow the same structure for every comment. I’ve extracted the ‘Comment ID’, ‘Received’ date time, ‘Correspondence Type’, and ‘Correspondence’ text into a dataframe. I’ve also truncated the longest comments (…comment 68 looks like someone copy and pasted their term paper) to 12,000. This will be important later because the context window for chatGPT is 4000 tokens.
EIS_comments %>% glimpse()
Rows: 2,776
Columns: 4
$ ID <dbl> 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29,…
$ Received <dttm> 2015-07-12 20:45:30, 2015-07-14 23:18:34, 2015-07-15 12:03:55, 2015-07-15 13:14:52, 2015-07-15 13:35:47, …
$ Correspondence <chr> "Web Form Correspondence", "Web Form Correspondence", "Web Form Correspondence", "Web Form Correspondence"…
$ Content <chr> "The alternatives are complete enough as a starting point. The issues will be related to the details. The …
We can do some basic summary analysis on these initial variables. The most comments were submitted in the week before the comment deadline on Sept 1. The vast majority of comments were received through the web form. Less than 10% of comments were physical letters and 51 of the 2777 comments were form cards given to Park visitors.
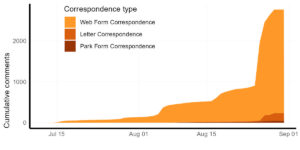
Often, large influxes of web and email comments are the product of advocacy groups encouraging their members to submit pre-written comments. I’ve used this tactic myself in conservation campaigns, so I won’t cast dispersions. But, I’ll also be the first to admit that a copy-and-pasted form letter is far less sincere than a uniquely crafted opinion.
After checking for matches among the comments, it is clear that there were two archetypical pre-written texts. These include 733 near identical comment in favor of wolf replacement (i.e. Alternative B), likely from National Parks Conservation Association:
EIS_comments %>%
+ filter(grepl("I care about the wildlife at our national parks, including the wolves and moose at Isle Royale. Right now there are only three", Content)) %>%
+ group_by(Content) %>%
+ tally() %>%
+ arrange(desc(n)) %>%
+ ungroup() %>%
+ filter(row_number() == 1) %>%
+ .$Content %>%
+ cat()
Dear Superintendent Green, I care about the wildlife at our national parks, including the wolves and moose at Isle Royale. Right now there are only three wolves left at the park- -the lowest number of wolves in more than 50 years- -threatening the overall ecosystem health of this iconic national park. I support management Alternative B to bring new wolves to the island, but urge the Park Service to do this as needed, rather than one time only. Without wolves, the moose population on the island will continue to increase, eating until the food sources are gone. If we bring new wolves to the island, they will help keep the moose population from rapidly expanding and minimize impacts to the native vegetation. This option is much less intrusive in this wilderness park than culling moose, removing moose from the island, or having to replant native vegetation once the moose consume it. As stewards of this park, the National Park Service should take the least intrusive action that results in the biggest benefit to the island's wildlife and ecosystem. I support the Park Service taking action to bring new wolves to the park immediately, before the population vanishes altogether. Thank you for considering my concerns. Sincerely,And 55 nearly identical comments in favor of Wilderness (i.e. Alternative A), likely from Wilderness Watch:
EIS_comments %>%
+ filter(grepl("Isle Royale's wilderness designation requires that we protect the area's unmanipulated, untrammeled wilderness character. Wild", Content)) %>%
+ group_by(Content) %>%
+ tally() %>%
+ arrange(desc(n)) %>%
+ ungroup() %>%
+ filter(row_number() == 1) %>%
+ .$Content %>%
+ cat()
Isle Royale's wilderness designation requires that we protect the area's unmanipulated, untrammeled wilderness character. Wilderness designation means we let Nature call the shots. Transplanting wolves from the mainland to Isle Royale is a major manipulation of the Isle Royale Wilderness and must not be done. Alternative Concept A, the No Action Alternative, is the best alternative to protect Isle Royale's unmanipulated, untrammeled wilderness character.It is important to flag these duplicated comments because the methods that we will use later on will not behave correctly with nearly identical strings.
EIS_comments_deduplicated <-
EIS_comments %>%
# Remove comments with no content
filter(!is.na(Content)) %>%
# Flag the web form duplicates
mutate(form_duplicate = ifelse(grepl("I care about the wildlife at our national parks, including the wolves and moose at Isle Royale. Right now there are only three", Content), "for Alt B", NA)) %>%
mutate(form_duplicate = ifelse(grepl("Isle Royale's wilderness designation requires that we protect the area's unmanipulated, untrammeled wilderness character. Wild", Content), "for Alt A", form_duplicate)) %>%
# Form duplicates are not exact matches
mutate(Content_dup = ifelse(is.na(form_duplicate), Content, form_duplicate)) %>%
group_by(Content_dup) %>%
# Retain one of the duplicate sets
slice_sample(n = 1)
After removing the duplicates and cleaning the data, we are left with 1970 unique comments.
Text analysis with chatGPT
Now, we can start analyzing the content. There are many ways that we could do this, depending on the question we want to answer. For instance, maybe we want to see with questions naturally group together to see if we can find common themes? Traditionally, a common way to do this type of natural language processing would be to use an approach like a Latent-Dirchelt allocation topic analysis that groups comments by tf-idf values of the stems of words contained in the comment. (I cover tf-idf in a previous post). But, one problems with this approach is that the context of words is lost.
If we want to capture the context of the text, we might try using word embeddings from a LLM like GPT. We’ll try this approach later.
In our case, maybe we just want to know how many comments support a given policy.. It would be hard to answer that from the embeddings ourselves, but we could treat GPT as an agent who could read and categorize comments by preferred policy alternative.
We’ll use two packages. httr helps us interact with the chatGPT API. The API speaks in json format. jsonlite helps us parse formatted prompts and responses.
library(httr) library(jsonlite)
Working with chatGPT is a lot like working with a new intern. Like an new intern, it has no prior contextual understanding of our specific task–we have to be very explicit with our directions. On the bright side, our chatGPT intern has endless patience and never sleeps!
We will be interacting with chatGPT through the API. This differs from the dialectical way that most people interact with chatGPT. We need to engineer our prompt to get a robust response in exactly the same format, every time. We can do that by passing in quite a bit of context in our prompt and giving specific directions for the output, with examples. Here is the prompt we’ll use:
You are a federal employee tasked with reading the following comment submitted by a member of the public in response to the The Isle Royale National Park Moose-Wolf-Vegetation Management Plan/EIS. The Plan/EIS is a document that evaluates management alternatives for the moose and wolf populations on the island National Park land.
Management alternatives include:
- Alternative A: No Action. Continue the current management of letting nature take its course, without any intervention or manipulation of the moose or wolf populations or their habitats.
- Alternative B: Immediate Wolf Introduction. Introduce 20-30 wolves over a three-year period, starting as soon as possible to reduce the moose population and its impacts on vegetation.
- Alternative C: Wolf Introduction after Thresholds are Met. Introduce wolves if certain thresholds are met, such as the extirpation of wolves, the overabundance of moose, or the degradation of vegetation. The number and timing of wolf introductions would depend on the conditions at the time.
- Alternative D: Moose Reduction and Wolf Assessment. Reduce the moose population by lethal and non-lethal means, such as hunting, contraception, or relocation. The goal would be to lower the moose density to a level that would allow vegetation recovery and assessing introducing wolves to the island in the future.
Here is the text of the public comment: '[INSERT COMMENT TEXT]'.
State which alternative the commenter is most likely to favor (A, B, C, D).
State if the comment is 'For', 'Against', or 'Neutral' on wolf introductions.
State if the strength of the commenter's opinion on a scale from 'Extremely strong', 'Very strong', 'Strong', 'Somewhat strong', or 'Mild'.
Produce the output in json format like this:
{
"favored_alternative": "",
"wolf_opinion": "",
"opinion_strength": ""
}ChatGPT 3.5 costs 0.002$ per 1000 tokens. We can use the OpenAI tokenizer to estimate the number of tokens constituting our input prompt.

Our input is 420 tokens. The output should be less than 50 tokens. So we can round to assume 500 tokens per query. So, it will cost us about $1 to process 1000 comments. Much cheaper than paying a human!
In the old days, you could pass a list of inputs into chatGPT ‘completions’ model all at once. This is no longer possible. Now, to use the ‘chat/completions’ API requires looping through each of the inputs and making individual requests. Unfortunately, the API often fails or hits the request rate limit. So, we need to be smart about staging and error handling with this larger loop. The structure of this loop is to define the prompt, wait 18 seconds to avoid the rate limit, run a tryCatch block to test if the API call fails, and if so, it skips to the next record and logs the records that the error occurred on, otherwise, parse the response and store the output in a file.
After getting initial responses, I also want to rerun 500 randomly selected comments in order to check chatGPT’s consistency. This is a critical part of using a generative model in quantitative analysis. I’ll talk more about this later.
Here’s the loop. It will take quite a while depending on your rate limit. I’d suggest either running it overnight or putting in on a remote server. Because we write each response out to file, there’s no problem if it fails. Just note the number of the last successful iteration (which will be printed to the screen) and start back up there.
set.seed(7097)
# Randomly select 500 records to resample
IDs_to_resample <- sample(unique(EIS_comments_deduplicated$ID), 500, replace = FALSE)
ID_list <- c(unique(EIS_comments_deduplicated$ID), IDs_to_resample)
# Create a vector to store failed IDs
failed_ids <- c()
ID_list <- Still_need_IDs
for (i in 1:length(ID_list)) {
ID_number = ID_list[i]
# Define the prompt
prompt_content <- paste0( "Here is the text of the public comment: '", EIS_comments_deduplicated %>%
filter(ID == ID_number) %>%
.$Content,
"'.
State which alternative the commenter is most likely to favor (A, B, C, D).
State if the comment is 'For', 'Against', or 'Neutral' on wolf introductions.
State if the strength of the commenter's opinon on a scale from 'Extremely strong', 'Very strong', 'Strong', 'Somewhat strong', or 'Mild'.
Produce the output in json format like this:\n{\n\"favored_alternative\": \"\",\n\"wolf_opinion\": \"\",\n\"opinion_strength\": \"\"\n}"
)
# Initialize gpt_response
gpt_response <- NULL
# With my account, I can make 3 requests per minute. To avoid denied API calls, I add a 18 second pause in each loop.
Sys.sleep(18)
tryCatch({
# Call GPT for a response
gpt_response <-
POST(
url = "https://api.openai.com/v1/chat/completions",
add_headers(Authorization = paste0("Bearer ", read_lines("../credentials/openai.key"))),
content_type_json(),
encode = "json",
body = list(
model = "gpt-3.5-turbo",
messages = list(
list(
"role" = "system",
"content" = "You are a federal employee tasked with reading the following comment submitted by a member of the public in response to the The Isle Royale National Park Moose-Wolf-Vegetation Management Plan/EIS. The Plan/EIS is a document that evaluates management alternatives for the moose and wolf populations on the island National Park land.
Management alternatives include:
- Alternative A: No Action. Continue the current management of letting nature take its course, without any intervention or manipulation of the moose or wolf populations or their habitats.
- Alternative B: Immediate Wolf Introduction. Introduce 20-30 wolves over a three-year period, starting as soon as possible to reduce the moose population and its impacts on vegetation.
- Alternative C: Wolf Introduction after Thresholds are Met. Introduce wolves if certain thresholds are met, such as the extirpation of wolves, the overabundance of moose, or the degradation of vegetation. The number and timing of wolf introductions would depend on the conditions at the time.
- Alternative D: Moose Reduction and Wolf Assessment. Reduce the moose population by lethal and non-lethal means, such as hunting, contraception, or relocation. The goal would be to lower the moose density to a level that would allow vegetation recovery and assessing introducing wolves to the island in the future."
),
list(
"role" = "user",
"content" = prompt_content
)
)
)
)
print(paste0("API call successful for ID: ", ID_number, ", index: ", i))
}, error = function(e) {
# Handle API call errors
cat("API call failed for ID: ", ID_number, ", index: ", i, "\n")
failed_ids <- c(failed_ids, i)
})
# If the API call was successful, proceed with data wrangling and output
if (!is.null(gpt_response)) {
# parse the response object as JSON
content <- content(gpt_response, as = "parsed")
# Assign the ID to the GPT response
gpt_response_df <- data.frame(
response_id = ID_number,
gpt_response = content$choices[[1]]$message$content
)
# Convert the JSON to a dataframe and join to the record data
output <- bind_cols( EIS_comments_deduplicated %>%
filter(ID == ID_number),
fromJSON(gpt_response_df$gpt_response) %>%
as.data.frame()
) %>%
mutate(response_created_time = Sys.time())
# Append the data to the extant records and write the output to a file. (This is a bit less memory efficient to do this within the loop, but I )
if (!file.exists("./EIS_GPT_responses.csv")) {
write.csv(output, "./EIS_GPT_responses.csv", row.names = FALSE)
} else {
read.csv("./EIS_GPT_responses.csv") %>%
mutate(across(everything(), as.character)) %>%
bind_rows(output %>%
mutate(across(everything(), as.character))
) %>%
write.csv("./EIS_GPT_responses.csv", row.names = FALSE)
}
print(paste0("Completed response ", i))
}
}
# Log the failed IDs to a file
if (length(failed_ids) > 0) {
write.csv(data.frame(ID = failed_ids), "./failed_ids.csv", row.names = FALSE)
cat("Failed IDs logged to 'failed_ids.csv'\n")
}
ChatGPT is nondeterministic, so your responses will differ. You can download the responses I got to follow along.
download.file(
url = "https://www.azandisresearch.com/wp-content/uploads/2023/09/Final_GPT_Responses.csv",
destfile = "./data/GPT_output.csv"
)
GPT_output <- read.csv("./data/GPT_output.csv")
GPT_output %>% glimpse()
Rows: 2,470
Columns: 13
$ ID <int> 93, 440, 2164, 636, 839, 2335, 36, 487, 1268, 2303, 1781, 60, 1033, 1948, 1826, 1538, 1685, 308, 22…
$ Received <chr> "7/29/2015 9:09", "8/9/2015 5:14", "8/27/2015 14:36", "8/18/2015", "8/25/2015", "8/28/2015 12:30", …
$ Correspondence <chr> "Web Form Correspondence", "Web Form Correspondence", "Web Form Correspondence", "Web Form Correspo…
$ Content <chr> "\"100% o wolves examined since 1994...have spinal anomalies.\"- -Of the six alternatives put forth…
$ form_duplicate <chr> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ Content_dup <chr> "\"100% o wolves examined since 1994...have spinal anomalies.\"- -Of the six alternatives put forth…
$ favored_alternative <chr> "C", "C", "Alternative D", "C", "C", "B", "C", "C", "D", "C", "Unknown", "C", "B", "A", "B", "A", "…
$ wolf_opinion <chr> "For", "Against", "Neutral", "For", "Neutral", "For", "For", "For", "Against", "For", "Neutral", "F…
$ opinion_strength <chr> "Very strong", "Very strong", "Strong", "Strong", "Somewhat strong", "Very strong", "Strong", "Stro…
$ response_created_time <chr> "32:19.2", "33:11.7", "33:16.9", "33:19.5", "34:35.2", "34:54.2", "34:55.4", "36:15.1", "36:16.3", …
$ Favored_alternative <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ Wolf_opinion <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
$ Opinion_strength <lgl> NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA, NA,…
A couple of interesting things to note here. First, I apparently was not specific enough in my instructions for classifying the favored alternative because chatGPT sometimes returns “Alternative B” instead of just “B”. This is one of the struggles with using chatGPT, a generative model, in this way. It strays from instructions just like human survey respondents when inputting free-text results. For example, common responses to the survey question, “How are you feeling on a scale from 1 (bad) to 10 (good)?” might be “I’m good” or “Okay” or “nine” or “0”. None of those answers fit the instructions, so we have to clean them up.
In the case of chatGPT, we might be able to reduce these errors with more specific prompt engineering. For now, we’ll just clean up the responses on the backend.
# Fix erroneous column names
GPT_output <-
GPT_output %>%
mutate(
favored_alternative = ifelse(is.na(favored_alternative), Favored_alternative, favored_alternative),
wolf_opinion = ifelse(is.na(wolf_opinion), Wolf_opinion, wolf_opinion),
opinion_strength = ifelse(is.na(opinion_strength), Opinion_strength, opinion_strength)
) %>%
select(
-Wolf_opinion,
-Favored_alternative,
-Opinion_strength
)
# There are probably more elegant ways to write generalized rules to classify these reponses, but this does the trick
GPT_output <-
GPT_output %>%
# Fix 'favored alternative' responses
mutate(
favored_alternative_edit = case_when(
(grepl(" and ", favored_alternative) | grepl(" or ", favored_alternative) | grepl("/", favored_alternative) | grepl("&", favored_alternative) | favored_alternative == "B, D") & !grepl(" and Wolf ", favored_alternative) & !grepl("N/A", favored_alternative) ~ "Multiple",
grepl("\\bAlternative A\\b", favored_alternative) | favored_alternative %in% c("A", "No Action (A)") ~ "A",
grepl("\\bAlternative B\\b", favored_alternative) | favored_alternative == "B" ~ "B",
grepl("\\bAlternative C\\b", favored_alternative) | favored_alternative %in% c("C", "Concept C") ~ "C",
grepl("\\bAlternative D\\b", favored_alternative) | favored_alternative == "D" ~ "D",
TRUE ~ "Other"
)
) %>%
# Fix 'opinion strength' responses
mutate(opinion_strength = tolower(opinion_strength)) %>%
mutate(
opinion_strength_edit = case_when(
opinion_strength %in% c("strong", "very strong", "mild", "somewhat strong", "extremely strong") ~ opinion_strength,
TRUE ~ "other"
)
) %>%
# Fix 'wolf opinion' responses
mutate(wolf_opinion = tolower(wolf_opinion)) %>%
mutate(
wolf_opinion_edit = case_when(
wolf_opinion %in% c("for", "against", "neutral") ~ wolf_opinion,
TRUE ~ "other"
)
)
Let’s take a look at the results.
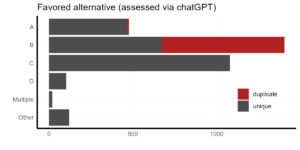 We can see that the majority of comments favor Alternative B: immediate wolf introduction. However, if we exclude the duplicated comments, our conclusion shifts to a majority in favor of the more moderate Alternative C: introduce wolves only after certain thresholds are met. Almost no one supports Alternative D: moose reduction and wolf assessment.
We can see that the majority of comments favor Alternative B: immediate wolf introduction. However, if we exclude the duplicated comments, our conclusion shifts to a majority in favor of the more moderate Alternative C: introduce wolves only after certain thresholds are met. Almost no one supports Alternative D: moose reduction and wolf assessment.
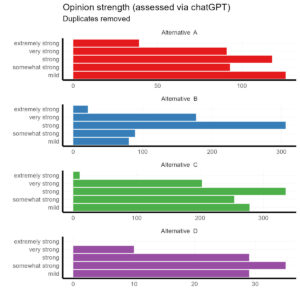 Comments that favored Alternative A were stronger proportionally. Alternative B supporters had mostly strong opinions but very few extremely strong or mild opinions. Supporters of Alternatives C and D were the least opinionated.
Comments that favored Alternative A were stronger proportionally. Alternative B supporters had mostly strong opinions but very few extremely strong or mild opinions. Supporters of Alternatives C and D were the least opinionated.
Validating chatGPT responses
It is worth asking ourselves how reliable chatGPT is at classifying these responses. One way to test this is to rerun a subset of comments, like we did above and check for agreement. This is called inter-rater reliability* (IRR).
* Although, maybe it should be called intra-rater reliability in this case. I guess it depends on out definition of ‘individual’ with LLM queries, but that’s a very philosophical bag of worms!
First, we need to subset our dataset to the responses that we scored twice.
IRR_comparisons <-
GPT_output %>%
group_by(ID) %>%
arrange(response_created_time) %>%
mutate(ID_row_count = row_number()) %>%
filter(ID_row_count <= 2) %>%
mutate(n = n()) %>%
filter(n > 1) %>%
ungroup()
Then we can see how reliably the favored alternative was scored,
IRR_comparisons %>%
select(ID, favored_alternative_edit, ID_row_count) %>%
pivot_wider(
id_cols = "ID",
names_from = "ID_row_count",
values_from = "favored_alternative_edit",
names_prefix = "val"
) %>%
group_by(val1 == val2) %>%
tally() %>%
mutate(
total = sum(n),
prop = n/total
)
# A tibble: 2 × 4
`val1 == val2` n total prop
<lgl> <int> <int> <dbl>
1 FALSE 2 500 0.004
2 TRUE 498 500 0.996
ChatGPT gave consistent responses in 498 out of 500 cases. That’s pretty good! Let’s look at the comments where it disagreed with itself.
IRR_comparisons %>%
select(ID, favored_alternative_edit, ID_row_count) %>%
pivot_wider(id_cols = "ID", names_from = "ID_row_count", values_from = "favored_alternative_edit", names_prefix = "val") %>%
filter(val1 != val2)
# A tibble: 2 × 3
ID val1 val2
1 288 C B
2 1160 B C
EIS_comments_deduplicated %>%
filter(ID == 288) %>%
.$Content %>%
cat()
There should be a balance between the wolf population and moose. When it is not balanced there is more harm than good done to the environment. Please introduce more wolves on this island instead of decreasing their population and this will keep the moose in check. Please add more wolves to contain the moose population. So many wolves are under attack in other states and decreasing their population is NOT the answer. It only creates more problems to the environment. There should be intense management of the wolf population to help it thrive and return the land back to it's natural state where there are enough moose and wolves. I think the public should be consulted as far as future plans for any culling. There should be intense management to monitor the effects of climate change as this will affect all aspects of wildlife and plant life on the island. I do not like the idea of a moose cull. I like the idea of introducing more wolves to the island so long as there is harmony with the existing wolves on the island. Maybe possibly try to introduce another type of animal that would be a good balance with the wolves and moose but only if it does not disrupt the balance and create new problems. Other states have adopted disastrous wolf culling plans that are only in the interests of farmers and ranchers. As the wolf population is dwindling, other problems will begin to develop as there is not a proper balance. Please keep wolves in mind and do your best to increase their population before it is too late and more animals will be needlessly killed without the proper balance of mother nature.>
EIS_comments_deduplicated %>%
filter(ID == 1160) %>%
.$Content %>%
cat()
I have heard both sides of this situation and I believe that new wolves should be introduced on Isle Royale. Climate change has made a large impact on the amount of ice that freezes in the Isle Royale region. Previously wolves from the mainland could cross the ice that formed and take up residence on the Isle. The ice hasn't been stable enough for these crossings in the last few years and the wolves are becoming inbred and dying off. If you will check a video that I have watched about the wolves being reintroduced to Yellowstone, you will see that the ecology of the region is benefited by the wolves being there. If enough wolves are transported to Isle Royale, the wolves will keep the moose in check and the ecology will improve. Allowing the pack to die off is really not a positive move. Introducing a new bloodline to the pack will help. I believe the wilderness designation of Isle Royale is a positive thing and that the wolves help to keep the ecosystem there in good order. Thank you for taking comments from the public.In both cases, chatGPT vacillated between classifying the comment as favoring alternative B or C. Difference between those alternatives is admittedly nuanced. Both alternatives propose replacing wolves, the only difference is in the timing. In Alternative B, wolves would be introduced immediately and in Alternative C wolve would be introduced, “if certain thresholds are met, such as the extirpation of wolves, the overabundance of moose, or the degradation of vegetation. The number and timing of wolf introductions would depend on the conditions at the time.”
Both of the comments that made chatGPT disagree with itself focus on the environmental conditions that wolf introductions might remedy. However, these comments seems to presuppose that those conditions have been met and seem to suggest immediate introduction is necessary. So, I can see where chatGPT might have a hard time solidly classifying these comments.
Let’s also check the IRR for chatGPT’s classification of ‘opinion strength.’ Unlike the favored alternative, where most folks explicitly stated their preference, classifying the strength of an opinion is a far more subjective task.
IRR_comparisons %>%
select(ID, opinion_strength_edit, ID_row_count) %>%
pivot_wider(
id_cols = "ID",
names_from = "ID_row_count",
values_from = "opinion_strength_edit",
names_prefix = "val") %>%
group_by(val1 == val2) %>%
tally() %>%
mutate(
total = sum(n),
prop = n/total
)
# A tibble: 2 × 4
`val1 == val2` n total prop
<lgl> <int> <int> <dbl>
1 FALSE 5 500 0.01
2 TRUE 495 500 0.99
ChatGPT disagreed with itself in 5 cases, but gave reliable classifications 99% of the time. That’s pretty good! However, just assessing binary disagreement or agreement isn’t a strong metric for this variable. A switch from “extremely strong” to “very strong” is less of an issue than a vacillating from “extremely strong” to “mild”.
Instead, we can use the Krippendorff’s Alpha. This metric provides a formal way to assess the the amount of inter-rater disagreement. There are multiple metrics that we could use, but Krippendorff’s Alpha is nice because it can generalize to any number of reviewers and can handle many types of disagreement (i.e. binary, ordinal, interval, categorical, etc.). Here’s a great post for understanding Krippendorff’s Alpha. We’ll use the irr package to estimate it.
library(irr)
The irr package needs the dataset in wide format matrix with one row per reviewer and each record (the package calls records ‘subjects’ because this metric is traditionally used in social science research) as a column. For this analysis, we’ll consider the first and second responses from chatGPT as individual reviewers. We also need to enforce the order of our opinion strength levels; otherwise, R will naturally order them alphabetically.
IRR_comparisons %>%
mutate(opinion_strength_edit = fct_relevel(
opinion_strength_edit,
c(
"other",
"mild",
"somewhat strong",
"strong",
"very strong",
"extremely strong"
)
)) %>%
select(
ID,
opinion_strength_edit,
ID_row_count
) %>%
pivot_wider(
id_cols = "ID_row_count",
names_from = "ID",
values_from = "opinion_strength_edit",
names_prefix = "ID_"
) %>%
select(-ID_row_count) %>%
as.matrix() %>%
kripp.alpha(method = "ordinal")
Krippendorff's alpha
Subjects = 500
Raters = 2
alpha = 0.996
Krippendorff’s Alpha ranges from -1 to 1, where 1 means perfect concordance, 0 means random guesses among reviewers, and -1 is perfect negative concordance. At .996, we are pretty near perfect reliability.
For many datasets, there will be a lower degree of IRR. But, it is important to remember to interpret the alpha value in context. Perfect concordance may not be realistic, especially in highly subjective classifications. In most cases our goals is not perfect concordance, but simply greater reliability than we’d get if we hired a bunch of humans to do the annotating. Preliminary evidence seems to indicate that even version 3.5 of chatGPT is more reliable than humans (even domain experts!) in subjective classification tasks.
In most cases, you won’t have the resources to get human annotations for an entire dataset for comparison. Instead, you could 1.) get human annotations for a small subset, 2.) use a similar benchmark dataset, or 3.) spot-check responses yourself. If you choose to spot check, I’d suggest rerunning chatGPT multiple times (> 3) in order to estimate the variance in responses. High variance responses indicate especially difficult classifications that you should target for spot-checks. Another tip is to ask chatGPT to return it’s justification with each response. Ultimately, this process will help you diagnose problematic types of responses and enable you to engineer better prompts to deal with those edge cases.
The bottom line is that working with chatGPT is less like working with a model and more like working with human raters–and all of the validation tasks that entails.
Analysis with token embeddings
Up to this point, we’ve presupposed the classifications we wanted ChatGPT to identify in our data. But, what if we wanted to uncover hidden categories in the responses? Folks could advocate for the same Alternative but for different reasons. For example, among those who favor Alternative C, some might argue from the perspective of climate change and some from the perspective of moose populations.
We can use token embeddings to uncover hidden clusters of topics in our responses. Embeddings are the way that LLMs encode free text into numeric form. Each token or ‘unit of language’ is numerically described as a position in multidimensional language space. This is a huge advantage over more traditional language clustering methods that simply count the occurrence of certain words. Embeddings retain the context of each token as it exists in the document.
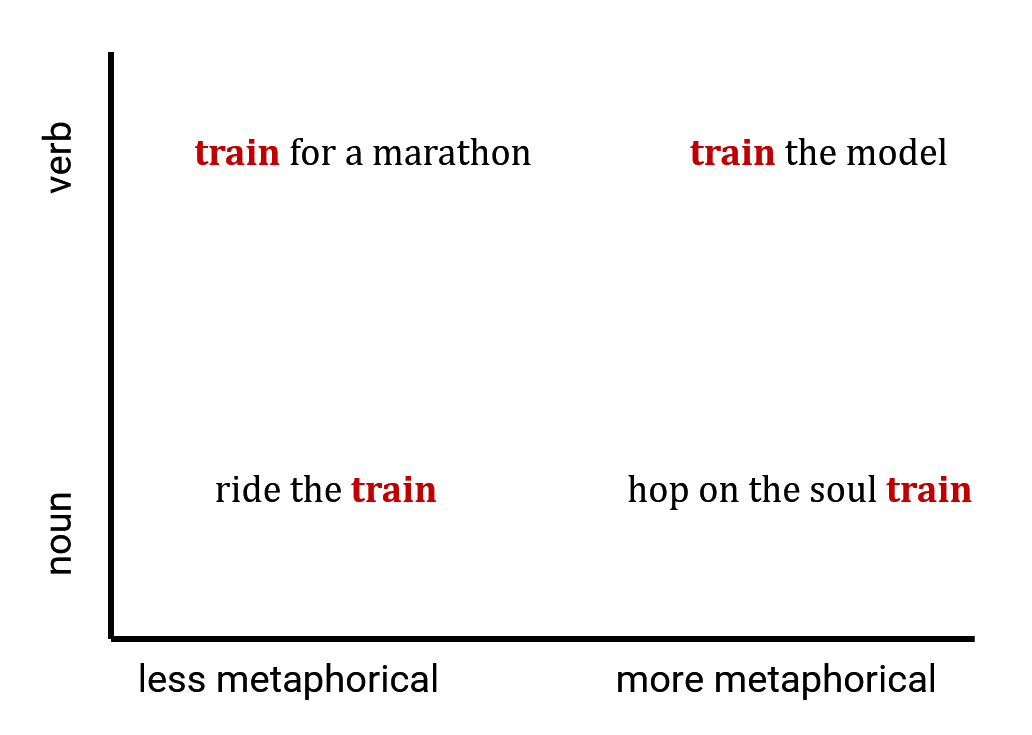
As a toy example, the word “train” in these sentences: “I train a model”, “I train for a marathon”, “I rode the train”, “I’m on the Soul Train” could be described in two dimensions of more or less metaphorical and noun/verb. If we do this for all of the words in a document or chunk of text, we can then think of all the embeddings as a point cloud. Documents with highly overlapping point clouds are more similar that those that don’t overlap at all.
We call a different OpenAI model, text-embedding-ada-002, to return the embeddings. Unlike the chat model, we can pass all of the responses as a list in a single call, instead of looping through each response. This makes embeddings much faster and cheaper than using the chatGPT API.
Prior to embedding, I like to remove non-alpha numeric characters from the text.
# Clean up the text to remove non-alpha numeric characters
input_to_embed <-
EIS_comments_deduplicated %>%
mutate(Content_cleaned = str_replace_all(Content, "[^[:alnum:]]", " "))
# Call OpenAI for the embeddings
embeddings_return <-
POST(
"https://api.openai.com/v1/embeddings",
add_headers(Authorization = paste0(
"Bearer ", read_lines("../credentials/openai.key"))
),
body = list(
model = "text-embedding-ada-002",
input = input_to_embed$Content_cleaned
),
encode = "json"
)
The returned object is a bit convoluted. We can use a bit of purrr and jsonlite to extract the embeddings.
# Extract the embeddings from the API return
embeddings_list <-
embeddings_return %>%
content(as = "text", encoding = "UTF-8") %>%
fromJSON(flatten = TRUE) %>%
pluck("data", "embedding")
Then add the embeddings back into the dataframe.
# Combine the embeddings with the original data
EIS_GPT_embeddings <-
EIS_comments_deduplicated %>%
as_tibble() %>%
mutate(
embeddings = embeddings_list,
ID = as.character(ID)
) %>%
left_join(
# We need to get only the first instance of the GPT response data, which also included the repeated reliability test responses, to know which alternative the comment favors
GPT_output %>%
group_by(ID) %>%
arrange(response_created_time) %>%
mutate(ID_row_count = row_number()) %>%
filter(ID_row_count == 1) %>%
ungroup() %>%
select(
ID,
favored_alternative_edit,
opinion_strength_edit
)
)
Topical clustering from text embeddings
The problem is that those point clouds exist in extremely high dimensions. OpenAI’s text-embedding-ada-002 model returns 1536 dimensions. We need a method to reduce that complexity into something useful.
As mentioned, the embeddings allow us to see how comments relate in high-dimensional language space. We want to figure out where there are denser clusters of point clouds in that space which indicate common themes in the comments.
A couple of common ways to do this is to use a clustering algorithm (e.g. K-means) or dimension reduction (e.g. PCA). For this tutorial I want to use a bit of a hybrid approach called t-SNE (t-distributed Stochastic Neighbor Embedding) that will allow us to easily visualize the clusters of common comments which we can then explore.
We’ll use Rtsne package which requires that the data be in matrix form.
library(Rtsne)
# Rtsne requires the embeddings to be in matrix form, so we extract the lists of emdeddings from the dataframe and convert them to matrix form.
openai_embeddings_mat <-
matrix(
unlist(
EIS_GPT_embeddings %>%
.$embeddings
),
ncol = 1536,
byrow = TRUE
)
# Estimate tSNE coordinates
set.seed(7267158)
tsne_embeddings <-
Rtsne(
openai_embeddings_mat,
pca = TRUE,
theta = 0.5,
perplexity = 50,
dims = 2,
max_iter = 10000
)
Determining the proper theta (i.e. learning rate) and perplexity (basically an estimate of how close points are in relation to the expected groupings) is more of an art than a science. This post does a great job of exploring choices for these parameters. By setting pca = TRUE in this case, we are first reducing the dimensionality to 50 principal components and then using tSNE to do the final reduction to two visual dimensions.
# Extract the tSNE coordinates and add them to the main dataset
EIS_GPT_embeddings <-
EIS_GPT_embeddings %>%
mutate(
tsne_dim1 = tsne_embeddings$Y[,1],
tsne_dim2 = tsne_embeddings$Y[,2]
)
# Visualize the tSNE plot
EIS_GPT_embeddings %>%
ggplot(aes(x = tsne_dim1, y = tsne_dim2)) +
geom_point(alpha = 0.5, pch = 16)
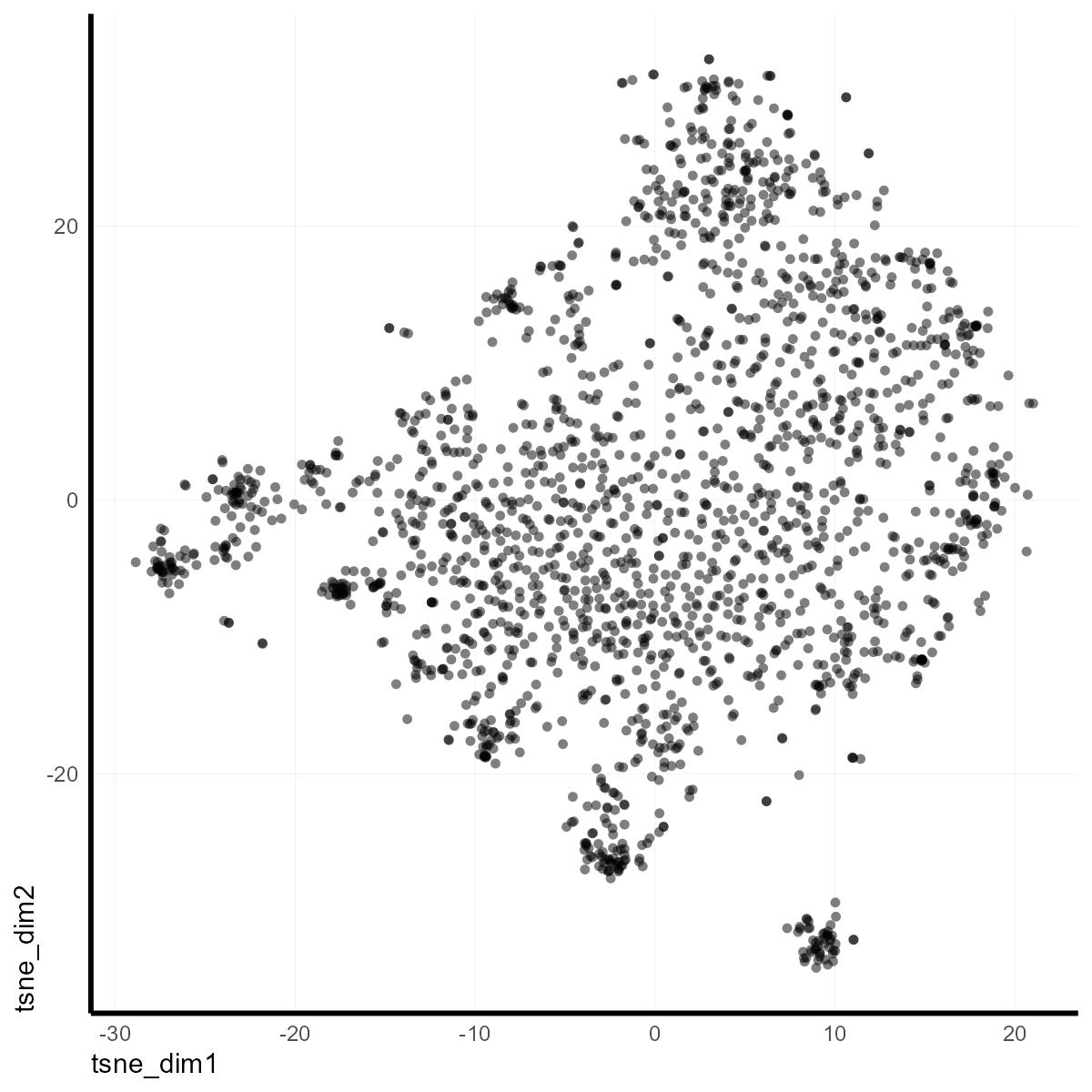
The first thing to note is that we are not seeing much discrete grouping of the points. This tells us that that the comments share a lot more in common across all comments than across local groups of comments. The second thing to notice is that despite the spread, we do see a handful of groups budding off along the periphery. In fact, one group in the bottom right is very distinct. It is important to remember that, unlike PCA, the axis dimensions in tSNE are meaningless. In fact, I’ll remove them from plot for the rest of the post. Position doesn’t matter in tSNE–only relative closeness.
At this point, we might want to manually delimit groups that we want to analyze further, like pulling out all of the comments from that cluster in the top left. To make this a bit easier, I’ve opted to cluster the two dimensional tSNE with hierarchical clustering. It is important to realize that this is purely a convenience for visualization. If we really wanted to use clustering to directly define groups (like hierarchical, KNN, etc.), it would make much more sense to cluster directly on the first 50 principle components.
tsne_embedding_clusters <-
hclust(
dist(tsne_embeddings$Y),
method = "average"
)
EIS_embeddings_clustered <-
EIS_GPT_embeddings %>%
mutate(
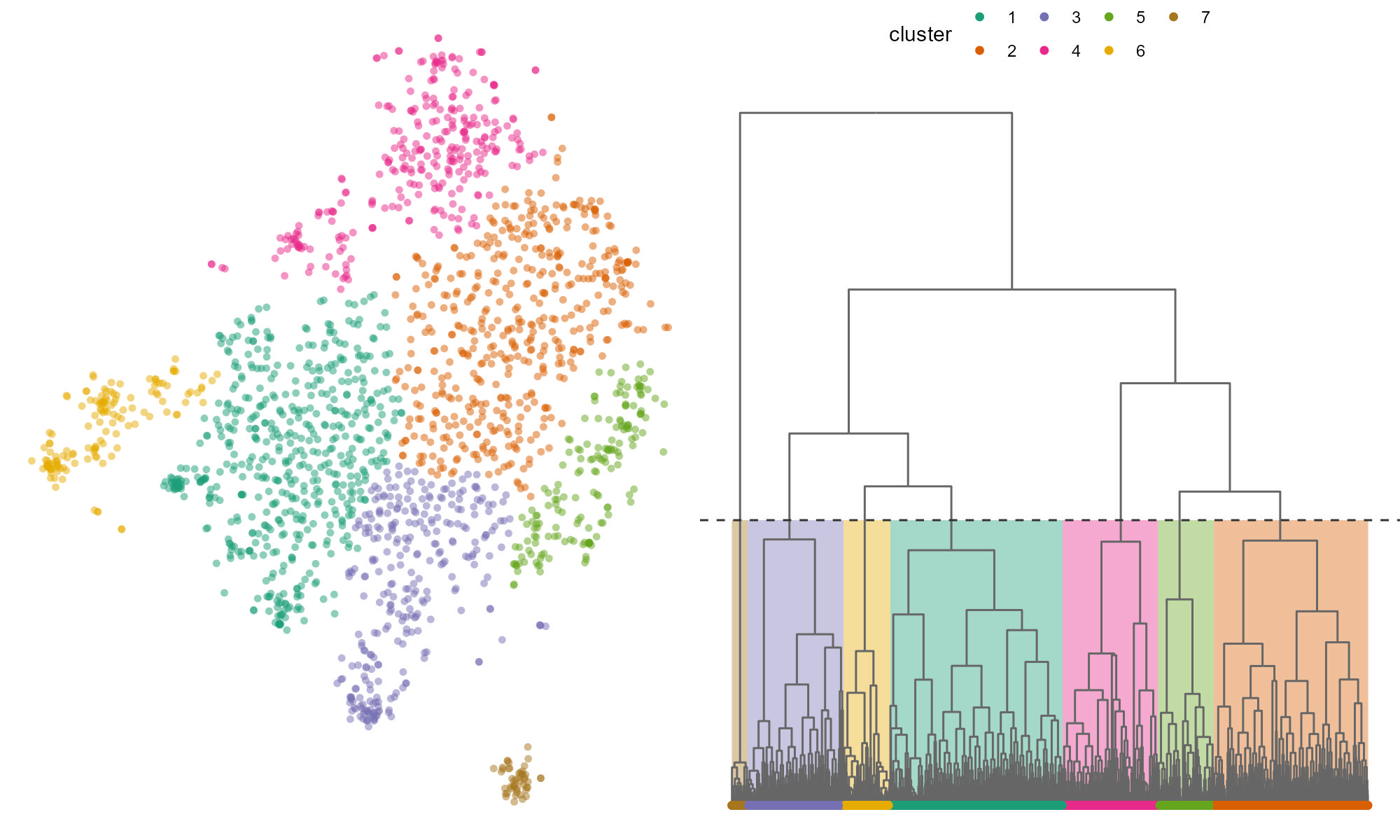
cluster = cutree(tsne_embedding_clusters, 7)
)
Since we are clustering on tSNE dimensions where distance doesn’t really matter, deciding where to set our breakpoint is a personal choice. I’ve decided to use 7 clusters because it seemed a natural breakpoint and recovered the obvious clusters.
Text analysis of topical clusters
Now that we have putative clusters of topics, we can perform some classic natural language processing (NLP) to illuminate the themes of those topics. We’ll use tidytext for this task.
library(tidytext)
First, we need to get the data into a long, tidy format where each word in every comments is its own row. We’ll also remove common stop words that are predefined in the tidytext library. Then, we can calculate the term frequency-inverse document frequency (TF-IDF) for the clusters. TF-IDF is basically a measure of how common a word is within a cluster, after accounting for how common a given words is overall.
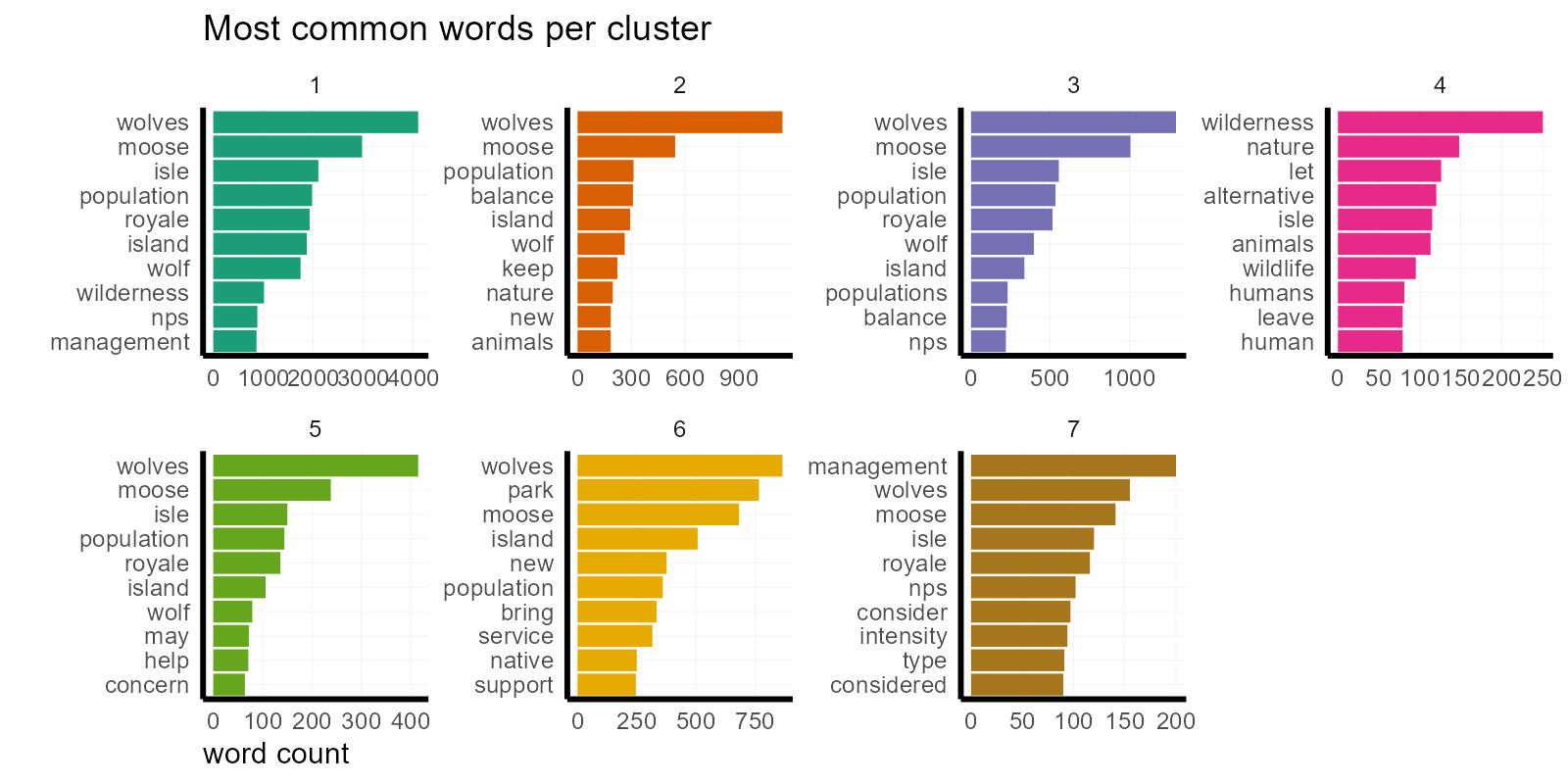
For example, if we take a look at the most common words in each cluster, it is unsurprising that “wolves”, “moose”, “isle” and “royale” dominate. (Although it is interesting that the top words for clusters 4 and 7 are “wilderness” and “management”… more on that later).
However, TF-IDF tells us about the relatively unique words that define a cluster of comments. Some clusters, like 1 and 2 have very even tf-idf distribution and the important words are mostly filler or nonsense words. This happens when clusters are saturated with common words and there is no strong theme producing uniquely important words. We could have guessed from the tSNE plot of the embeddings that the bulk of comments in the center of the plot would fall in this lexical no-man’s-land. But! Clusters 3, 4, 5, and 7 show promisingly skewed distributions.
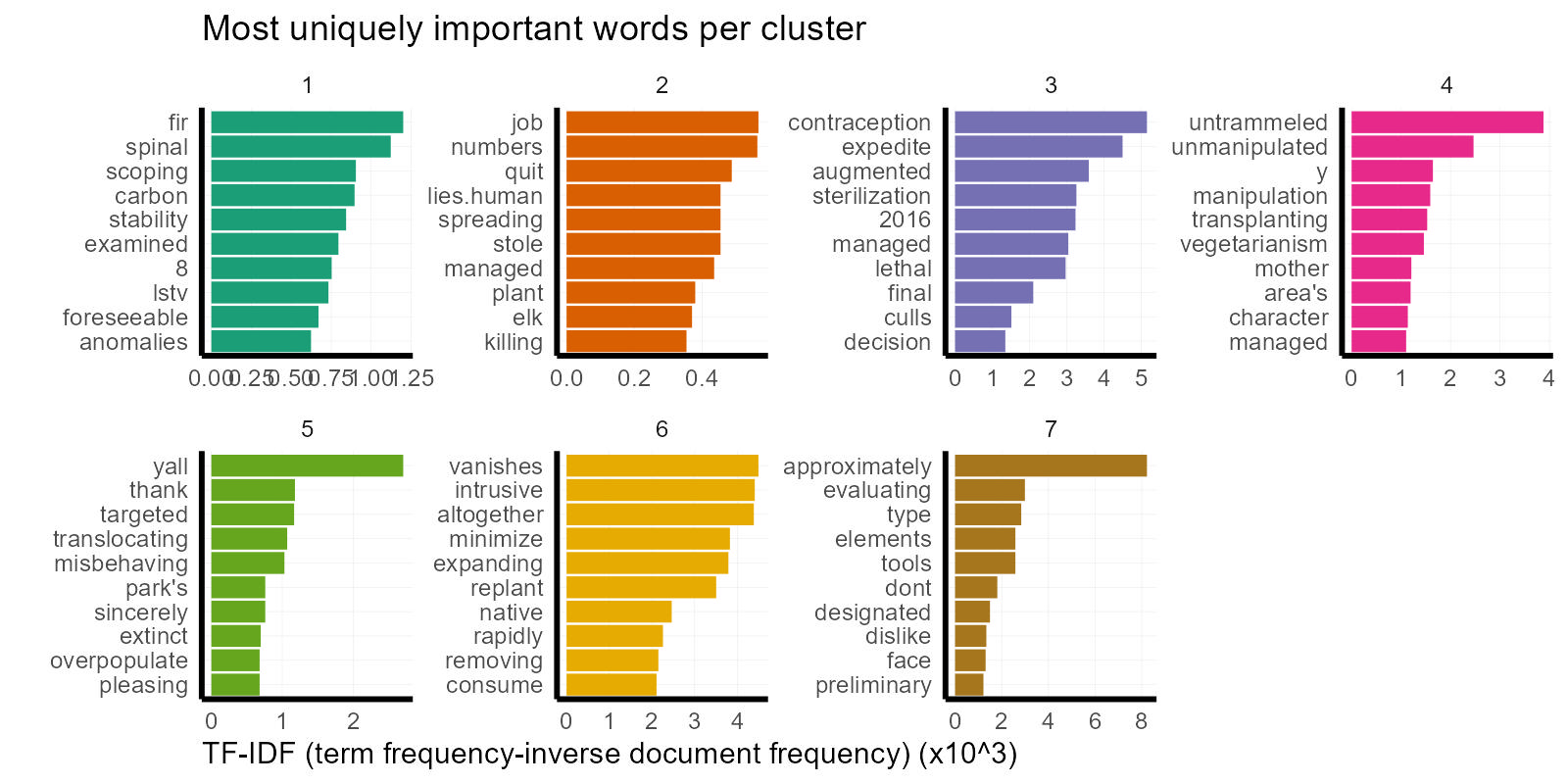
Cluster 3 seems to orient towards a topic of animal welfare, with words like, “contraception”, “sterilization”, “lethal”, and “culls”. I suspect that these comments speak to folks’ concerned less about the wolf population or wilderness management, and more about the ethics of any proposed action involving animals. In a similar way, it looks like Cluster 7 is more concerned with the science and measurement behind the management decision and less about the decision itself with words like, “evaluating”, “approximately”, and “tools” with high uniqueness and “management” as the most common word overall. These topics would have been completely lost if we had stopped at categorizing favored alternatives.
Meanwhile cluster 4 appears to be squarely concerned with Wilderness issues. “Wilderness” and “nature” are the most common words in this cluster and “untrammeled” and “unmanipulated” are the most uniquely important words. We might expect that most of the comments that chatGPT categorizes as favoring alternative A will fall into cluster 4.
We can also take a look at how the clusters map onto the chatGPT categorizations.
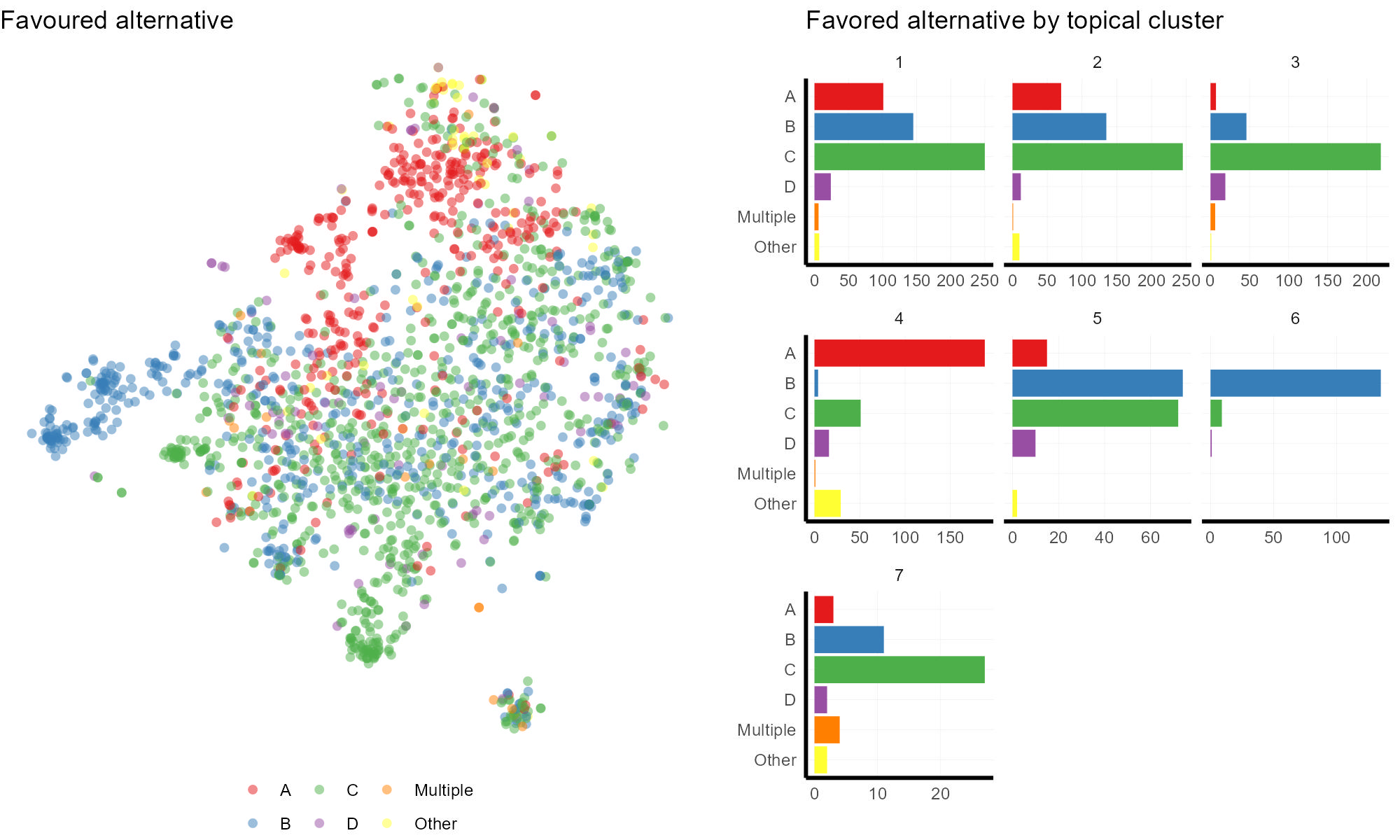
Mappin the chatGPT categorized ‘favored alternative’ onto the tSNE coordinates, we can see that comments roughly sort by favored alternative. Cluster 6 is almost entirely defined by support for Alternative B – immediate wolf introduction. Cluster 4, which seemed to orient towards Wilderness values is mostly comprised of comments in support of Alternative A – no action.
Cluster 7 and Cluster 3, are mostly skewed to Alternative C – more monitoring, but exhibit very similar distributions. This might be a great example where even folks who tend to agree on the same Alternative, do so for different reasons–a pattern we would have totally missed without text analysis.
The remaining clusters which compose the bulk of the midland in the tSNE plot favor a mix of Alternatives.
Chain-of-density summarization
We can learn a lot from looking at common and important words and using our human judgement to piece together the topical theme of each cluster. Ideally, we would read all of the comments in a cluster to develop a topical summary. But that would take a long time. As an alternative, we can pass all of the comments in a given cluster to an LLM and have it summarize the theme.
Currently, only a handful of models support context windows large enough to digest the entirety of the comments in our clusters. Anthropic’s Claude2 has a context widow of up to 100k tokens (rough 75,00 words). Although, it isn’t quite as good at chatGPT 4. To get the most out of Claude2, we can use a special type of prompting developed for summarization called “chain-of-density”. Chain-of-density prompting forces the model to recurrently check it’s own output to maximize the density and quality of its summarization. Research shows that people tend to like the chain-of-density summaries even better than human-written summaries of new articles.
For demonstration, we’ll use chain-of-density prompting to summarize the theme of cluster 3. Here is the prompt that we will pass to Claude2:
"You will generate increasingly concise entity-dense summaries of the semicolon separated comments included below.
The comments were submitted by a member of the public in response to the The Isle Royale National Park Moose-Wolf-Vegetation Management Plan/EIS. The Plan/EIS is a document that evaluates management alternatives for the moose and wolf populations on the island National Park land.
Now that you know the context, here are the semicolon separated survey response:
[INSERT SEMICOLON SEPARATED COMMENTS]
Instructions: You will generate increasingly concise entity-dense summaries of the above semicolon separated comments. Repeat the following 2 steps 5 times.
Step 1: Identify 1-3 informative entities (delimited) from the comments which are missing from the previously generated summary.
Step 2: Write a new denser summary of identical length which covers every entity and detail from the previous summary plus the missing entities.
A missing entity is
- Relevant: to the main themes of the comments.
- Specific: descriptive yet concise (5 words or fewer).
- Novel: not in the previous summary.
- Faithful: present in the comments.
- Anywhere: located in the comments.
Guidelines:
- The first summary should be long (7 - 5 sentences, ~100 words), yet highly non-specific, containing little information beyond the entities marked as missing. Use overly verbose language and fillers (e.g., 'these comments discuss') to reach ~100 words.
- Make every word count. Rewrite the previous summary to improve flow and make space for additional entities.
- Make space with fusion, compression, and removal of uninformative phrases like 'these comments discuss'.
- The summaries should become highly dense and concise, yet self-contained, e.g., easily understood without having read the comments.
- Missing entities can appear anywhere in the new summary.
- Never drop entities from the previous summary. If space cannot be made, add fewer new entities.
Remember: Use the exact same number of words for each summary.
Answer in JSON. The JSON should be a list (length 5) of dictionaries whose keys are 'missing_entities' and 'denser_summary'."I don’t have API access to Claude2, but unlike chatGPT, Claude2 accepts files as input. So, it is easy to output our prompt with the contained comments as a .txt file and submit it to Claude2 manually.
Claude2 gives us five increasingly dense summaries:
Summary 1: These comments provide a range of perspectives on how the National Park Service should manage the declining wolf population and increasing moose population on Isle Royale. There is discussion of various preliminary alternative concepts, including taking no action, reintroducing wolves once, maintaining both moose and wolves, reducing the moose population, and intensively managing the moose population. Many commenters express support for alternative C, which involves reintroducing and augmenting the wolf population on Isle Royale more than once if necessary. There is also frequent mention of the possibility of relocating problem wolves from elsewhere to the island. Overall, most commenters emphasize the importance of restoring the natural wolf/moose balance on Isle Royale through wolf reintroduction rather than intensively managing the moose population.Summary 2: These comments provide perspectives on managing the declining Isle Royale wolf and increasing moose populations. Many support alternative C to reintroduce and augment wolves more than once if needed. Wolf relocation from the mainland is also mentioned. Most emphasize restoring the wolf/moose balance through wolf reintroduction rather than intensively managing moose. Climate change reducing ice bridges for wolf migration and the wilderness designation of Isle Royale are frequently discussed. Many oppose lethal moose culling, instead supporting moose contraception/sterilization. Overall there is a focus on restoring the natural predator-prey dynamic through wolf reintroduction while minimizing intensive human management due to the wilderness designation.Summary 3: These comments discuss managing the declining Isle Royale wolf and increasing moose populations. Many support alternative C to reintroduce and augment wolves more than once if needed to restore the wolf/moose balance. Wolf relocation and genetics are often mentioned given reduced migration from climate change. The wilderness designation and opposition to lethal moose culling are frequently discussed, with support for contraception/sterilization. There is concern about moose overbrowsing without sufficient wolves. Some mention wolf tourism benefits. Overall there is emphasis on restoring the natural predator-prey dynamic and wolf genetics through reintroduction while minimizing intensive human management due to the wilderness designation.Summary 4: These comments discuss managing the declining Isle Royale wolf and increasing moose populations, often supporting alternative C to reintroduce and augment wolves more than once to restore balance. Wolf relocation and genetics are frequently mentioned to compensate for reduced migration from climate change. Many oppose lethal moose culling, instead supporting contraception/sterilization, expressing concerns about moose overbrowsing and ticks without wolves. Some mention wolf tourism benefits and preserving the wilderness designation. There is emphasis on restoring balance through wolf reintroduction to limit moose impacts on vegetation while minimizing intensive human management.Summary 5: These comments frequently support alternative C to reintroduce and augment Isle Royale wolves to restore wolf/moose balance and predator-prey dynamics, concerned about moose overbrowsing, ticks, and vegetation without sufficient wolves. Wolf relocation and genetics are often proposed to compensate for reduced migration from climate change. Many oppose lethal moose culling, noting wilderness values. Some mention continuing the iconic predator-prey research, wolf tourism benefits, wolf-livestock issues, and the value of public engagement. Overall there is emphasis on reestablishing a healthy Isle Royale wolf population through reintroduction to minimize intensive human management and moose impacts.The final two summaries start to get at the nuance particular to this cluster. Summary 4 mentions, “Many oppose lethal moose culling, instead supporting contraception/sterilization”. Summary 5 mentions: “Many oppose lethal moose culling, noting wilderness values.” As expected, much of the summary is likely common across all comments. So, a human interpretation of the summaries is still necessary.
Conclusion
In this post, we explored using chatGPT, text embeddings, and Claude2 to analyze public comments on a complex environmental management decision. We learned methods to responsibly validate chatGPT output. While not perfect, chatGPT showed promising reliability at categorizing free-form opinions. The text embeddings allowed us to uncover hidden topical clusters among comments that traditional methods would have missed. Claude2’s long context window allowed us to further interpret the topical clusters. Together, these tools enabled a nuanced quantitative analysis of subjective text data that would be infeasible for a single human analyst to perform manually.